Acadêmicos desenvolvem benchmark de testes para LLMs em inteligência de ameaças cibernéticas
Os modelos de linguagem grande (LLMs) são cada vez mais utilizados para aplicações de defesa cibernética, embora as preocupações com a sua fiabilidade e precisão continuem a ser uma limitação significativa em casos de utilização críticos.

ma equipe de pesquisadores do Instituto de Tecnologia de Rochester (RIT) lançou o CTIBench, o primeiro benchmark projetado para avaliar o desempenho de LLMs em aplicações de inteligência contra ameaças cibernéticas.
“Os LLMs têm o potencial de revolucionar o campo de CTI ao aprimorar a capacidade de processar e analisar grandes quantidades de dados não estruturados de ameaças e ataques, permitindo que analistas de segurança utilizem mais fontes de inteligência do que nunca”, escreveram os pesquisadores.
“No entanto, [eles] são propensos a alucinações e mal-entendidos de texto, especialmente em domínios técnicos específicos, que podem levar à falta de veracidade do modelo. Isso exige a consideração cuidadosa do uso de LLMs em CTI, pois suas limitações podem levá-los a produzir inteligência falsa ou não confiável, o que pode ser desastroso se usado para lidar com ameaças cibernéticas reais.”
Embora já existam benchmarks de LLM no mercado, eles são muito genéricos (GLUE, SuperGLUE, MMLU, HELM) para medir objetivamente as aplicações de segurança cibernética ou muito específicos (SECURE, Purple Llama CyberSecEval, SecLLMHolmes, SevenLLM) para aplicar a inteligência de ameaças cibernéticas.
Essa falta de benchmark ad-hoc de LLM para aplicações CTI levou os pesquisadores do RIT a desenvolver o CTIBench.
O que é CTIBench?
Os pesquisadores descreveram o CTIBench como “um novo conjunto de tarefas de benchmark e conjuntos de dados para avaliar LLMs em inteligência de ameaças cibernéticas”.
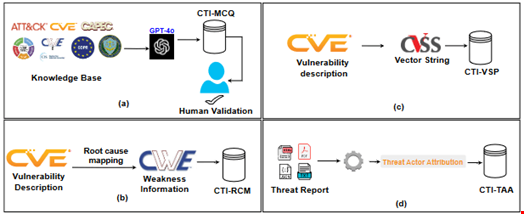
O produto final é composto por quatro blocos de construção:
- Perguntas de múltipla escolha sobre inteligência contra ameaças cibernéticas (CTI-MCQ)
- Mapeamento de causa raiz de inteligência de ameaças cibernéticas (CTI-RCM)
- Previsão de gravidade de vulnerabilidade de inteligência de ameaças cibernéticas (CTI-VSP)
- Atribuição de Atores de Ameaças de Inteligência de Ameaças Cibernéticas (CTI-TAA)
Criando perguntas de múltipla escolha usando GPT-4
O primeiro passo no processo de desenvolvimento do CTIBench consistiu na criação de uma base de dados de avaliação de conhecimento.
Para criar este banco de dados, os pesquisadores coletaram dados de uma série de fontes autorizadas dentro do CTI, como as estruturas cibernéticas do Instituto Nacional de Padrões e Tecnologia dos EUA (NIST), o modelo Diamond de detecção de intrusão e regulamentos como o Regulamento Geral Europeu de Proteção de Dados ( GDPR).
Este banco de dados de conhecimento ajudou-os a criar questões de múltipla escolha para avaliar a compreensão dos LLMs sobre padrões de CTI, ameaças, estratégias de detecção, planos de mitigação e melhores práticas.
Os pesquisadores formularam perguntas usando padrões CTI como STIX e TAXII , frameworks CTI como MITRE ATT&CK e Common Attack Pattern Enumerations and Classifications (CAPEC), e o banco de dados common weakness enumeration (CWE).
Eles então geraram a lista final de perguntas de múltipla escolha usando GPT-4 e a avaliaram e validaram manualmente.
O conjunto de dados final consiste em 2.500 perguntas, das quais 1.578 foram coletadas do MITRE, 750 do CWE, 40 da coleta manual e 32 de padrões e estruturas.
Mapeamento de causa raiz, previsão e atribuição de gravidade de vulnerabilidade
Com o CTIBench , os pesquisadores propuseram duas tarefas práticas de CTI que avaliam o raciocínio e as habilidades de resolução de problemas dos LLMs:
- Mapeamento de descrições de vulnerabilidades e exposições comuns (CVE) para categorias CWE comuns (ou seja, CTI-RCM)
- Cálculo da gravidade das vulnerabilidades usando pontuações do sistema de pontuação de vulnerabilidade comum (CVSS) (ou seja, CTI-VSP)
Por fim, eles forneceram uma ferramenta solicitando ao LLM que analisasse relatórios de ameaças disponíveis publicamente e os atribuísse a agentes de ameaças específicos ou famílias de malware (ou seja, CTI-TAA).
ChatGPT 4 LLM de melhor desempenho testado com CTIBench
Eles testaram cinco LLMs de uso geral diferentes usando o CTIBench: ChatGPT 3.5, ChatGPT 4, Gemini 1.5, Llama 3-70B e Llama 3-8B.
O ChatGPT 4 recebeu os melhores resultados para todas as tarefas, exceto previsão de gravidade de vulnerabilidade (CTI-VSP), para a qual o Gemini 1.5 foi o modelo de melhor desempenho.
Apesar de ser de código aberto, o LLAMA3-70B tem desempenho comparável ao Gemini-1.5 e até o supera em duas tarefas, embora tenha dificuldades na tarefa CTI-VSP.
“Através do CTIBench, fornecemos à comunidade de investigação uma ferramenta robusta para acelerar a resposta a incidentes, automatizando a triagem e análise de alertas de segurança, permitindo-lhes concentrar-se em ameaças críticas e reduzindo o tempo de resposta”, concluíram os investigadores.






