Container Escape to Shadow Admin: vulnerabilidades do ‘autopilot’ do GKE
Em fevereiro de 2021, o Google anunciou o Autopilot , um novo modo de operação no Google Kubernetes Engine (GKE).

Sumário executivo
Com o Autopilot, o Google oferece uma experiência Kubernetes “prática”, gerenciando a infraestrutura de cluster para o cliente. A plataforma provisiona e remove automaticamente os nós com base no consumo de recursos e aplica as melhores práticas seguras do Kubernetes prontas para uso.
Em junho de 2021, os pesquisadores da Unidade 42 divulgaram várias vulnerabilidades e técnicas de ataque no GKE Autopilot para o Google. Os usuários capazes de criar um pod podem ter abusado deles para (1) escapar de seu pod e comprometer o nó subjacente, (2) escalar privilégios e se tornar administradores de cluster completos e (3) persistir secretamente o acesso administrativo por meio de backdoors que são completamente invisíveis ao cluster operadores.
Um invasor que obteve uma posição inicial em um cluster do Autopilot, por exemplo, por meio de uma conta de desenvolvedor comprometida, poderia ter explorado esses problemas para aumentar privilégios e se tornar um “administrador sombra”, com a capacidade de exfiltrar secretamente segredos, implantar malware ou criptomineradores e interromper as cargas de trabalho.
Após nossa divulgação, o Google corrigiu os problemas relatados, implantando patches universalmente no GKE. Todos os clusters do Autopilot agora estão protegidos.
Este blog fornece uma análise técnica dos problemas, bem como mitigações para evitar ataques semelhantes contra ambientes Kubernetes e GKE.
| Produto afetado | Piloto automático do Google Kubernetes Engine (GKE) |
| Tópicos Relacionados da Unidade 42 | Fuga de Contêiner , Nuvem |
Informações sobre o ‘autopilot’ do GKE
O piloto automático é um novo modo de operação no GKE, oferecendo o que o Google descreve como uma experiência “interna” do Kubernetes. No GKE Standard, os clientes gerenciam a infraestrutura de cluster e pagam por nó. Com o GKE Autopilot, o Google cuida da infraestrutura de cluster e os clientes pagam apenas pelos pods em execução. Isso permite que os clientes se concentrem em suas aplicações, reduzindo os custos operacionais.
Em poucas palavras, a infraestrutura de cluster gerenciada significa que o Google automaticamente:
- Provisiona e ajusta o número de nós de acordo com o consumo de recursos de seus pods.
- Aplica uma política integrada para garantir que o cluster siga as práticas recomendadas de segurança e possa ser gerenciado com segurança pelo Google.
Abaixo está um diagrama simplificado da arquitetura do Autopilot. Os componentes exclusivos do Autopilot são coloridos em verde e mostrados com um número correspondente à sua função na lista acima. Ao contrário do GKE Standard, em que os nós são visíveis como VMs do Compute Engine, os nós do Autopilot são totalmente gerenciados pelo Google e, portanto, coloridos em verde.
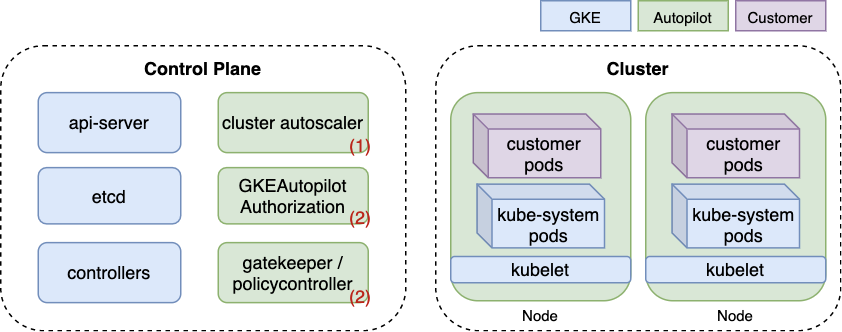
Conforme visto na Figura 1, dois componentes reforçam a política do Autopilot. O primeiro é um OPA Gatekeeper validando o webhook de admissão, um projeto de código aberto amplamente usado para aplicação de políticas no Kubernetes. O segundo é um modo de autorização proprietário do Kubernetes chamado GKEAutopilot, que o Google implementou modificando o código-fonte do Kubernetes.
A política integrada tem duas finalidades : (a) impedir que os usuários acessem os componentes do cluster gerenciados pelo Google, como nós; e (b) manter as melhores práticas seguras do Kubernetes. Por exemplo, o Autopilot proíbe a execução de contêineres privilegiados, atendendo a (a) e (b).
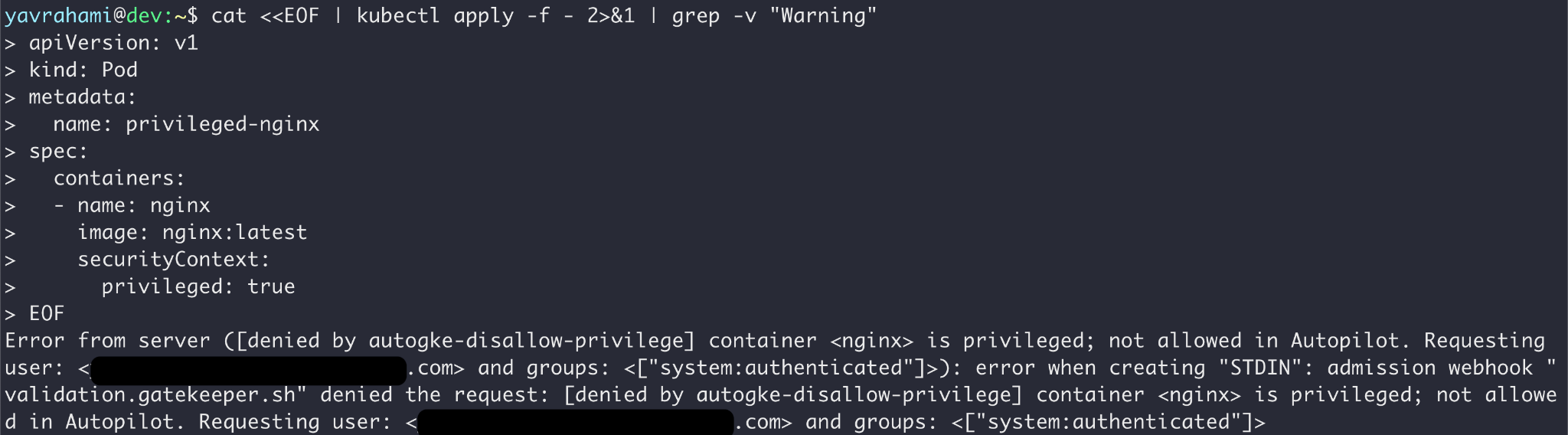
A política do Autopilot vai além da prevenção de fugas de contêineres. As Figuras 3, 4 e 5 destacam alguns exemplos interessantes. A documentação do GKE lista todos os limites impostos pela política.


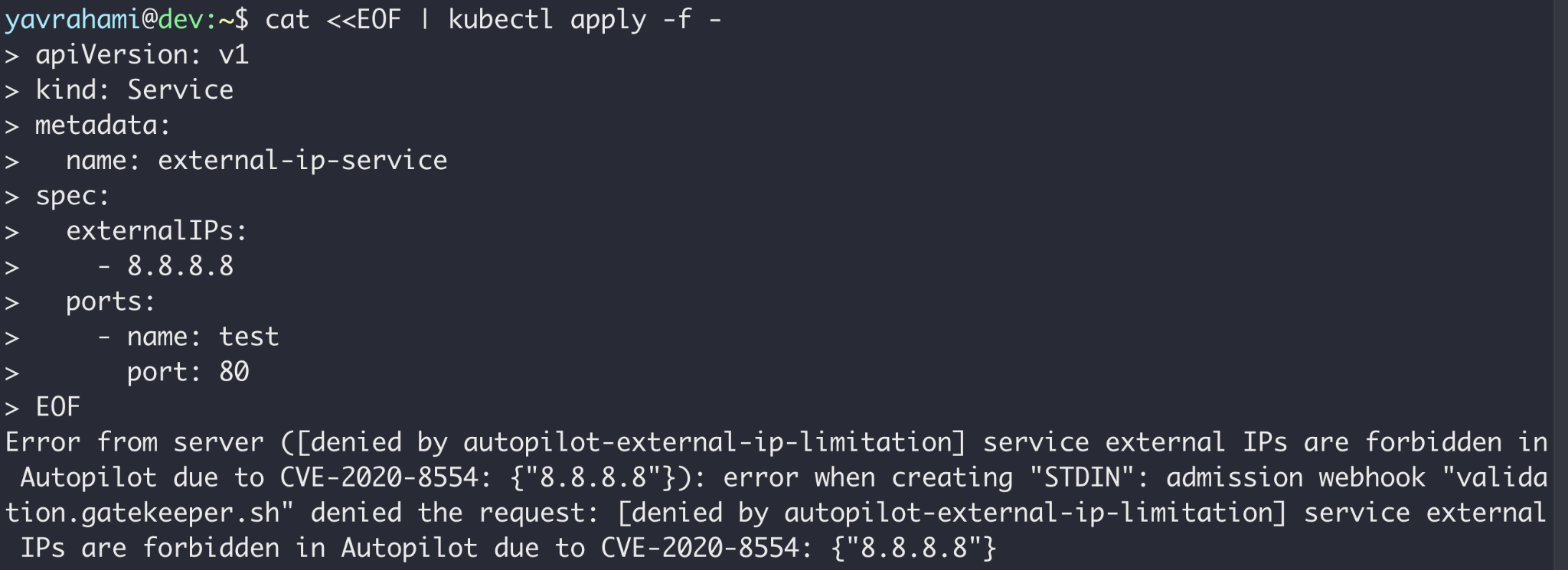
Lendo as mensagens de erro nas Figuras acima, você pode ver que o Gatekeeper impediu as operações nas Figuras 2 e 5, enquanto o modo de autorização GKEAutopilot impediu as operações nas Figuras 3 e 4.
Superfícies de ataque exclusivas do piloto automático do GKE
A política integrada do Autopilot bloqueia vários caminhos de exploração prontos para uso, oferecendo uma melhor postura de segurança em comparação com o Kubernetes padrão ou o GKE Standard. Dito isto, também cria superfícies de ataque exclusivas para o Autopilot:
- Os administradores podem confiar na política do Autopilot para evitar configurações arriscadas. Se os invasores puderem contornar essa política de alguma forma, eles poderão escalar privilégios por meio de métodos que os clientes esperam que sejam bloqueados, como implantar um contêiner privilegiado.
- Os administradores do Autopilot não são totalmente privilegiados, restringidos pela política interna de acessar nós e certas APIs privilegiadas do Kubernetes. Se os invasores puderem ignorar a política do Autopilot, eles poderão obter privilégios mais altos do que os administradores, abrindo a porta para backdoors invisíveis.
As seções a seguir apresentam vulnerabilidades, técnicas de escalonamento de privilégios e métodos de persistência que identificamos que se enquadram nessas superfícies de ataque. Encadeados, eles permitem que um usuário restrito que pode criar um pod para (1) comprometer nós, (2) escalar privilégios para um administrador de cluster irrestrito e (3) instalar backdoors invisíveis e persistentes no cluster.
Mascarando-se como cargas de trabalho permitidas para comprometer nós
Nossa pesquisa começou no seguinte parágrafo na documentação do Autopilot:
“Nossa intenção é impedir o acesso não intencional à máquina virtual do nó. Aceitamos envios nesse sentido por meio do Programa de recompensa de vulnerabilidade do Google (VRP)…”
Isso parecia um desafio interessante, então criamos um cluster de piloto automático e começamos a procurar. O Autopilot instalou o OPA Gatekeeper no cluster junto com várias políticas (chamadas “restrições” na terminologia do Gatekeeper) encarregadas de evitar configurações arriscadas, como contêineres privilegiados. O cluster também tinha uma Custom Resource Definition (CRD) que parecia interessante, chamada allowlistedworkloads .

Conforme mostrado anteriormente na Figura 2, o Autopilot proíbe configurações de pod que possam permitir fugas de contêiner. Para dar suporte a complementos que exigem algum nível de acesso ao nó, o Autopilot criou uma noção de cargas de trabalho permitidas na lista. Se um contêiner corresponder a uma carga de trabalho permitida na lista, ele poderá usar os recursos privilegiados especificados na configuração de carga de trabalho permitida . Em junho, as únicas cargas de trabalho permitidas eram os agentes Datadog.

Abaixo está a configuração de carga de trabalho permitida para um dos agentes Datadog que chamou nossa atenção. Se um contêiner especificar o comando e a imagem listados, ele poderá montar os caminhos de host listados em volumes somente leitura.
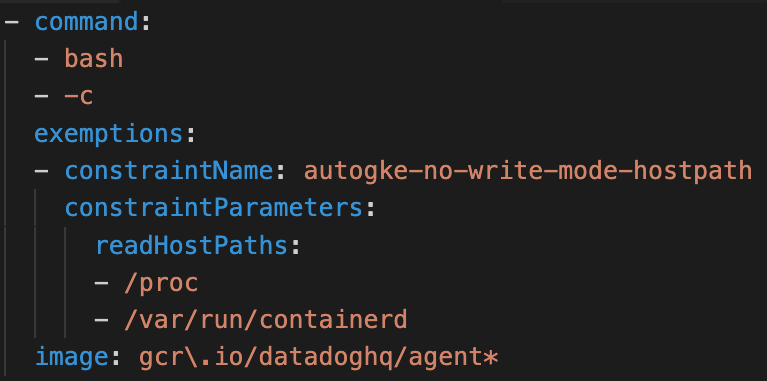
O problema aqui é a verificação insuficiente. Apenas verificar o comando e a imagem não é suficiente para garantir que o contêiner execute o código Datadog. Usando o PodSpec a seguir , um contêiner pode se disfarçar como o agente Datadog enquanto executa o código controlado pelo invasor e abusar dos volumes de host expostos para quebrar.
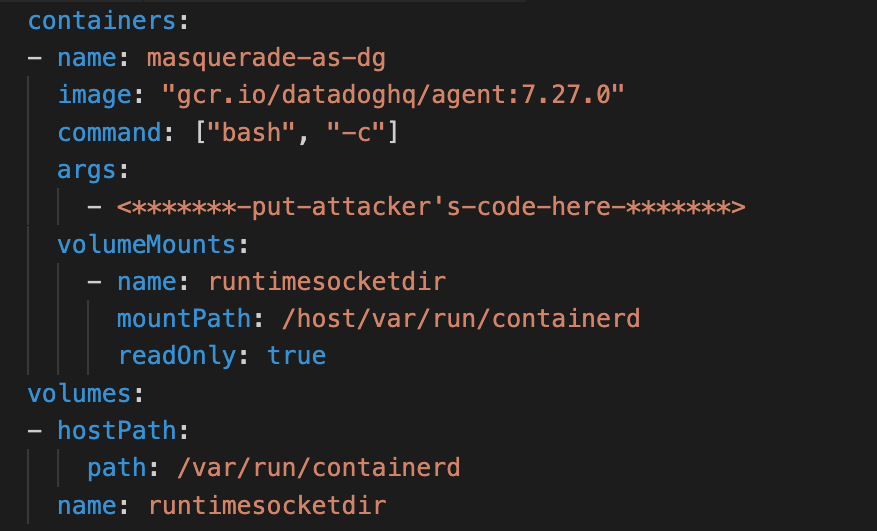
No vídeo abaixo, um usuário mal-intencionado implanta um pod disfarçado de agente Datadog. O pod assume seu nó subjacente por meio das seguintes etapas:
- Abuse do soquete containerd montado para criar um container privilegiado que monta o sistema de arquivos do host.
- Faça com que esse contêiner privilegiado instale um serviço systemd que gere um shell reverso do nó para uma máquina controlada pelo invasor.
Vídeo 1. Mascarado como uma carga de trabalho permitida para comprometer o nó subjacente.
Impacto do Comprometimento do Nó
Um invasor que pode criar um pod pode explorar esse problema para criar contêineres maliciosos que escapam e assumem seus nós subjacentes. Os usuários do piloto automático esperam que a plataforma evite esse tipo de ataque e serão pegos de surpresa.
O comprometimento do nó abre os seguintes vetores de ataque:
- O invasor imediatamente obtém controle sobre os pods vizinhos e seus tokens de conta de serviço, aumentando potencialmente os privilégios e se espalhando para outros namespaces .
- O invasor pode consultar o endpoint de metadados da instância do nó para obter um token de acesso. Por padrão, esse token fornece acesso de leitura ao armazenamento em nuvem no projeto do cliente.
- Como os administradores do Autopilot não podem acessar os nós, os invasores podem abusar desse problema para instalar malware ou criptomineradores ocultos neles. No entanto, o Autopilot dimensiona automaticamente os nós, portanto, garantir que o malware persista não é simples.
- O invasor obtém acesso às credenciais subjacentes do Kubelet, permitindo visibilidade de quase todos os objetos do cluster.
Por fim, como o Autopilot cobra apenas por pods em execução, os usuários habilidosos podem ter abusado desse problema para reduzir alguns custos, executando algumas cargas de trabalho diretamente nos nós. Aconselhamos reduzir as contas de maneiras mais legítimas.
Escalando para administradores irrestritos
Seguindo a trajetória de um intruso motivado, procuramos métodos confiáveis de escalar essa fuga de contêiner para uma tomada completa do cluster. Ao comprometer um nó, os invasores podem roubar os tokens da conta de serviço dos pods vizinhos. Naturalmente, faria sentido segmentar nós que hospedam pods com contas de serviço poderosas. Esses podem ser pods implantados pelo usuário ou, mais interessante, pods do sistema implantados nativamente em todos os clusters do Autopilot.
Depois de examinar a política integrada, descobrimos que o Autopilot isenta completamente as contas de serviço do sistema kube . Isso tornou os pods do sistema kube os alvos mais interessantes, pois os tokens roubados podiam ser usados livremente sem se preocupar com a política.
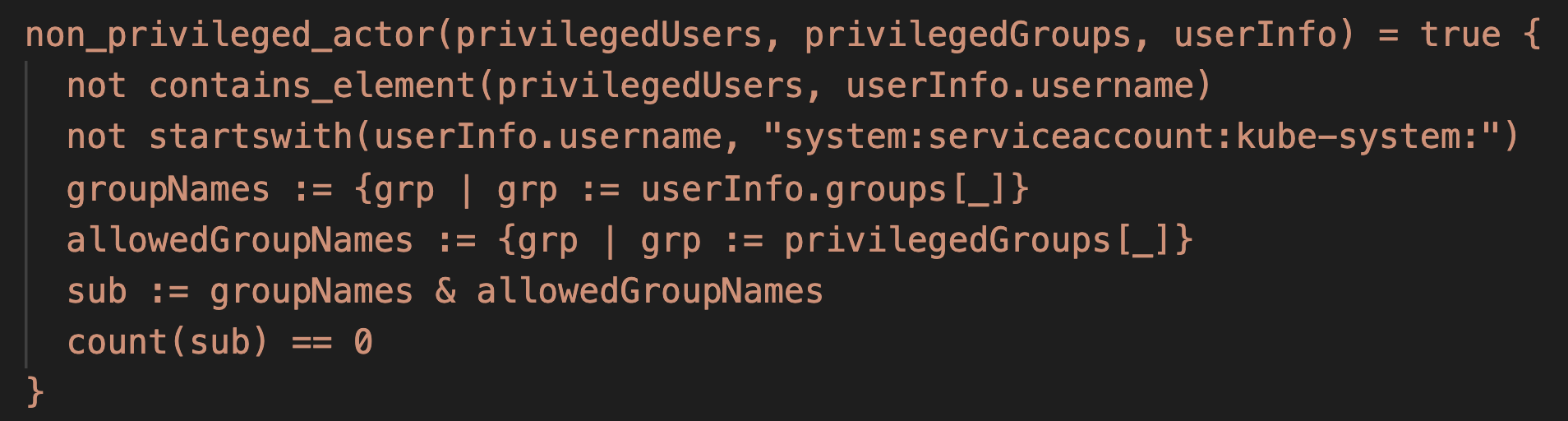
Para procurar pods poderosos no Autopilot, criamos o sa-hunter , uma ferramenta Python que mapeia as contas de serviço dos pods para suas permissões do Kubernetes (ou seja, funções e funções de cluster). As ferramentas existentes vinculam contas de serviço a suas permissões, mas não mostram se algum pod realmente usa uma determinada conta de serviço. A Figura 11 mostra um exemplo de saída de sa-hunter :
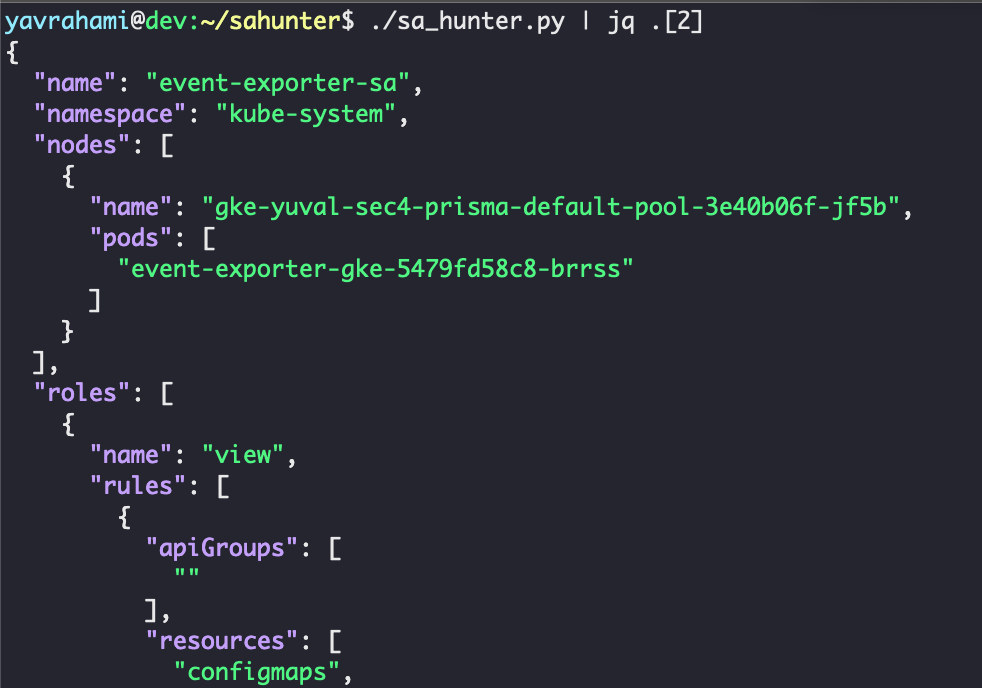
O sa-hunter encontrou dois poderosos pods do sistema kube instalados por padrão: stackdriver-metadata-agent-cluster-level e métricas-server . Ambos os pods podem atualizar as implantações existentes, conforme mostrado na Figura 12. Esse privilégio pode parecer inocente à primeira vista, mas é suficiente para escalar para um administrador de cluster completo. Curiosamente, esses pods também são implantados por padrão no GKE Standard, tornando a técnica de escalonamento de privilégios a seguir relevante para todos os clusters do GKE, Standard e Autopilot .
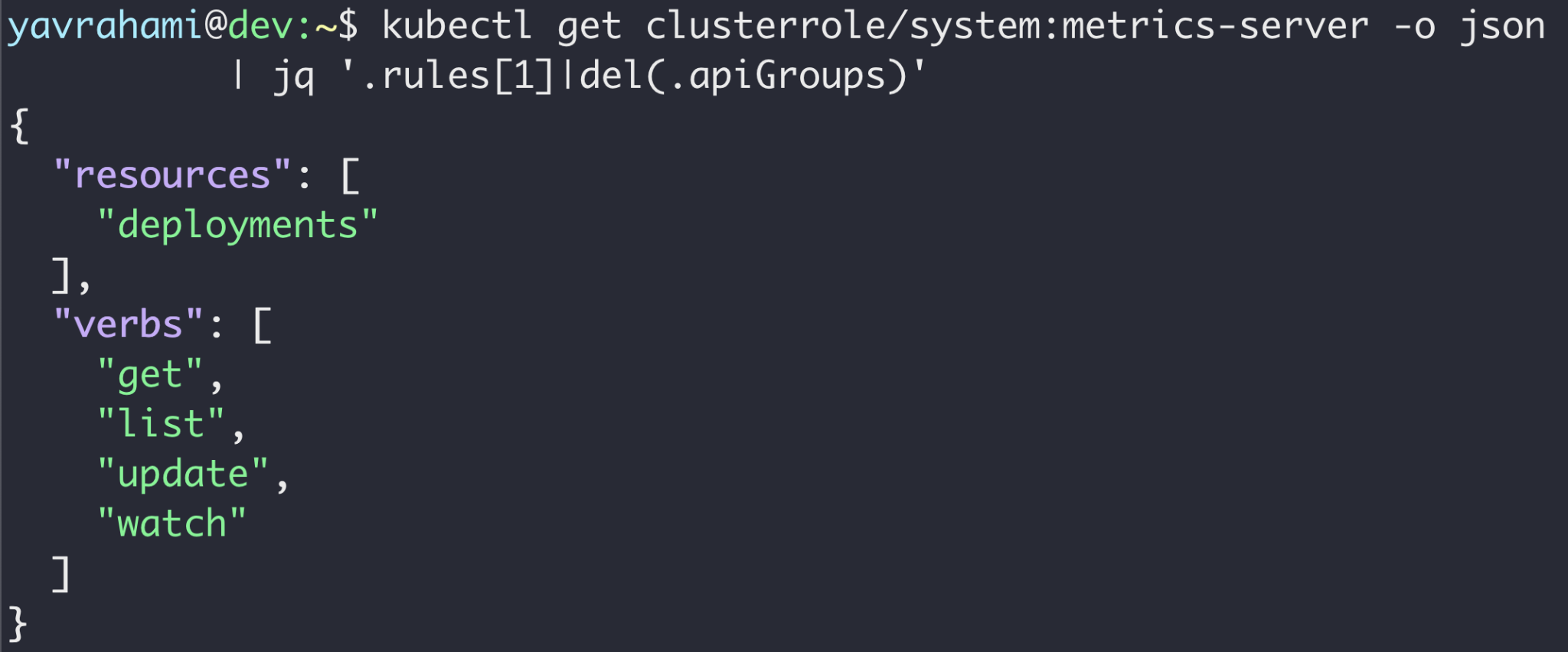
Depois de assumir um nó que hospeda o pod stackdriver-metadata-agent-cluster-level ou o pod de servidor de métricas , um invasor pode coletar seu token de conta de serviço do sistema de arquivos do nó. Armado com esse token, o invasor pode obter os privilégios de qualquer conta de serviço no cluster com três etapas simples:
- Atualize a conta de serviço de uma implantação existente para a conta de serviço de destino. Há várias implantações pré-instaladas, qualquer uma das quais pode ser usada para esta etapa.
- Adicione um contêiner malicioso a essa implantação.
- Faça com que esse contêiner malicioso recupere o token da conta de serviço de destino montado no contêiner em /run/secrets/kubernetes.io/serviceaccount/token .

Para que isso seja uma escalada de privilégios significativa, o invasor precisa ter como alvo uma conta de serviço poderosa. O namespace kube-system oferece várias contas de serviço pré-instaladas e extremamente poderosas para você escolher. A conta de serviço clusterrole-aggregation-controller ( CRAC ) é provavelmente a principal candidata, pois pode adicionar permissões arbitrárias a funções de cluster existentes.
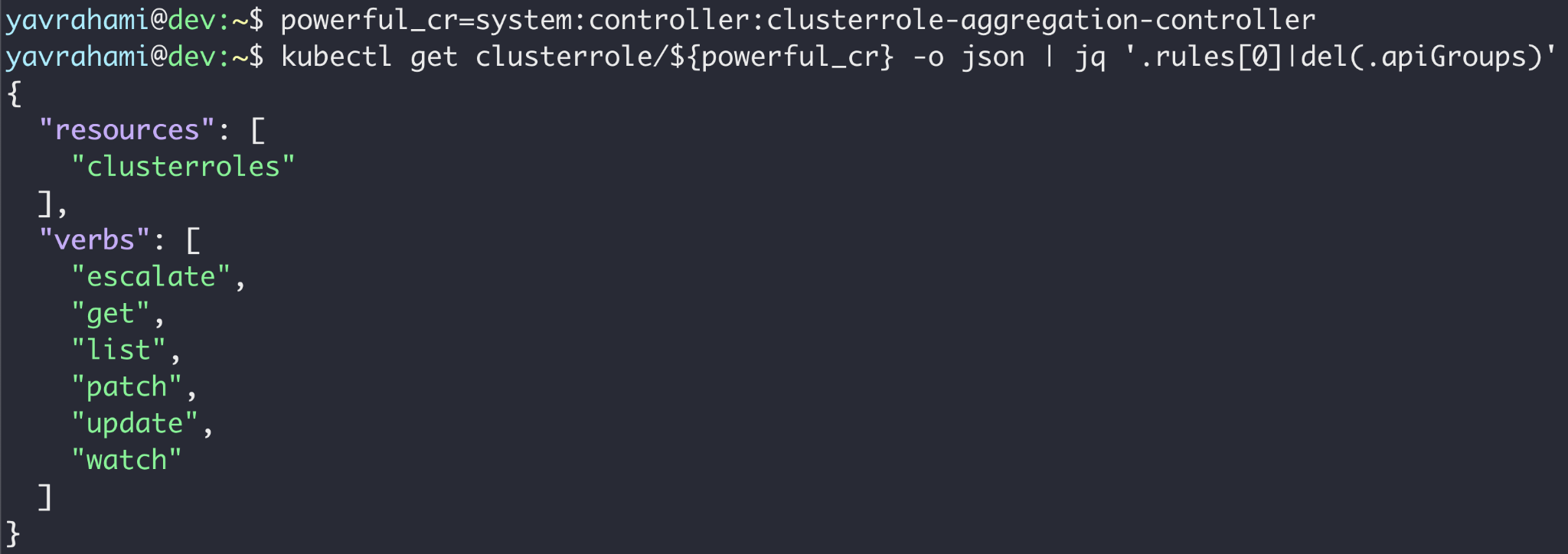
Após usar a técnica ilustrada na Figura 13 para obter o token do CRAC , o invasor pode atualizar a função do cluster vinculada ao CRAC para possuir todos os privilégios. Nesse ponto, o invasor é efetivamente o administrador do cluster e também está isento da política do Autopilot (como visto na Figura 10).
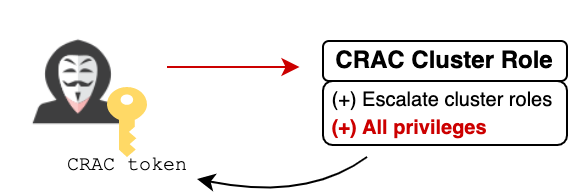
Rebobinando, se o invasor quiser encadear essa técnica de escalonamento de privilégios com a fuga de contêiner discutida anteriormente, ele precisa agendar de alguma forma seu pod de breakout em um nó que hospeda o pod de stackdriver-metadata-agent-cluster-level ou o pod de servidor de métricas . Embora o Autopilot rejeite pods que tenham nodeSelectors , ele permite a forma mais simples de atribuição de nó — o campo nodeName .
O campo nodeName garante que o pod de breakout chegará ao nó de destino, desde que tenha recursos adequados para outro pod. Mesmo que não haja espaço no nó de destino, o invasor ainda tem algumas opções. Ele pode (1) observar o nó de destino e esperar que um pod seja excluído; ou (2) crie pods para acionar um aumento de nó, enganando o autoescalador do Autopilot para redistribuir cargas de trabalho para que um pod poderoso termine em um nó mais vazio.
Cadeia completa: backdoors invisíveis via webhooks de admissão mutante
O vídeo 2 mostra a cadeia de ataque completa, combinando a fuga do contêiner com a rota de escalonamento de privilégios integrada ao GKE. Após a exploração, o invasor tem privilégios mais altos do que os administradores do Autopilot, pois está isento da política integrada (como visto na Figura 10). Este nível de acesso pode ser abusado para instalar backdoors invisíveis e persistentes na forma de webhooks de admissão mutantes .
Os webhooks de admissão mutantes recebem todos os objetos criados ou atualizados no cluster, incluindo pods e segredos. Se isso não for assustador o suficiente, esses webhooks também podem alterar arbitrariamente qualquer objeto recebido, tornando-os um backdoor ridiculamente poderoso. Conforme mostrado anteriormente na Figura 4, os administradores do Autopilot não podem listar webhooks de admissão em mutação e, portanto, nunca verão esse backdoor.
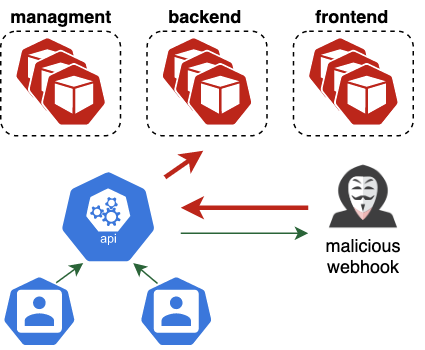
Vídeo 2. Escalando da criação do pod para um administrador irrestrito e um backdoor invisível .

Cadeia Completa: Impacto
Antes das correções, os invasores poderiam ter explorado os problemas apresentados para transformar uma violação limitada em um controle completo do cluster em qualquer cluster do Autopilot. Usando webhooks que são invisíveis para os usuários, os invasores podem manter secretamente seu acesso administrativo, tornando-se efetivamente “administradores de sombra”. Nesse ponto, eles podem ter secretamente exfiltrado segredos, implantado malware ou criptomineradores e interrompido cargas de trabalho.
Outros problemas
Durante nossa pesquisa, encontramos dois problemas adicionais que permitem o comprometimento do nó, mas com menor impacto. O primeiro envolve dois nomes de contas de serviço no namespace padrão que foram isentos da política do Autopilot: csi-attacher e otelsvc . Se um invasor obtivesse controle sobre o namespace padrão, seria possível criar essas contas de serviço para ignorar a política interna. O invasor pode então criar pods privilegiados para comprometer os nós e usar a técnica de escalonamento de privilégio discutida para assumir o controle de todo o cluster.
O segundo ataque explorou o CVE-2020-8554 por meio dos serviços do Load Balancer para comprometer os nós, mas exigiu privilégios de administrador para explorar. O cenário de ataque aqui é um invasor que já comprometeu um cluster do Autopilot e está tentando contornar a política interna para estabelecer um backdoor secreto.
Correções e Mitigações
Seguindo nosso conselho e ao longo dos últimos meses, o Google implantou várias correções e mitigações no GKE Autopilot. Eles impedem o ataque relatado e protegem a plataforma contra explorações semelhantes.
- Os administradores de cluster agora podem listar, visualizar e até criar webhooks de admissão mutantes, evitando seu abuso como backdoors invisíveis.
- O Google reforçou o processo de verificação de cargas de trabalho permitidas na lista .
- A aplicação de políticas mudou do OPA Gatekeeper para o controlador de políticas do Google, permitindo que os clientes implantem sua própria instância do Gatekeeper. Os clientes agora podem aplicar sua própria política em cima da política integrada. Como defesa em profundidade e para mitigar possíveis problemas futuros , recomendamos a implantação das mesmas políticas que você implantaria no padrão GKE.
- A política interna não é mais visível.
- As contas de serviço csi-attacher e otelsvc não estão mais isentas da política do Autopilot.
- O Google abriu uma política para o OPA Gatekeeper que restringe os poderosos pods do sistema kube abusados no ataque. A política impede que esses pods atribuam uma nova conta de serviço a um pod existente. Consulte o guia de proteção do GKE para mais informações.
É altamente recomendável ler o comunicado oficial do Google , que descreve os problemas da perspectiva do Google e lista suas mitigações.
Como evitar ataques semelhantes em ambientes Kubernetes
O ataque apresentado pode ser classificado como uma escalação de privilégios do Kubernetes, onde um invasor com acesso limitado obtém permissões mais amplas sobre um cluster. Esse tipo de atividade subsequente do invasor deve começar a partir de uma violação inicial: uma imagem maliciosa na cadeia de suprimentos do cluster, um serviço vulnerável exposto publicamente, credenciais roubadas ou uma ameaça interna. Proteger a cadeia de fornecimento de software, as identidades e o perímetro externo de seu cluster pode reduzir as chances de tais violações ocorrerem em seus clusters.
Atacantes sofisticados ainda podem encontrar maneiras criativas de se infiltrar em clusters. A solução proativa de configurações incorretas comuns, como Kubelets que permitem acesso não autenticado, pode reduzir significativamente a superfície de ataque interna disponível para um invasor. Controles de segurança, como NetworkPolicies e PodSecurityStandards , restringem e desmoralizam ainda mais os agentes mal-intencionados.
Na cadeia de ataque apresentada, o invasor teve que comprometer apenas um nó para assumir o controle de todo o cluster. O problema subjacente não eram as permissões do nó, mas as dos pods poderosos que ele hospedava, que incluíam a capacidade de atualizar implantações. Essa permissão e outras podem parecer restritas à primeira vista, mas são equivalentes ao administrador do cluster.
Pods poderosos ainda são comuns em clusters de produção : instalados nativamente pela plataforma Kubernetes subjacente ou introduzidos por meio de complementos populares de código aberto. Se um nó que hospeda um pod poderoso for comprometido, o invasor poderá coletar facilmente o token de conta de serviço poderoso do pod para espalhar no cluster.
Lidar com pods poderosos é complexo, principalmente porque suas permissões podem ser legitimamente necessárias. A primeira etapa é a detecção — identificando se existem pods poderosos em seu cluster. Esperamos que o sa-hunter possa ajudar com isso e planejamos lançar ferramentas adicionais que se concentrem na detecção automática de pods poderosos.
Se você identificou pods poderosos em seu cluster, recomendamos seguir uma das abordagens abaixo:
- Se você gerencia o pod poderoso, considere se é possível remover privilégios desnecessários de sua conta de serviço ou defini-los para namespaces ou nomes de recursos específicos.
- Se esses pods fizerem parte de uma solução externa, entre em contato com o provedor ou projeto de nuvem relevante para reduzir os privilégios do pod. Se o pod for implantado por um serviço gerenciado do Kubernetes, talvez seja possível substituí-lo por um controlador de plano de controle.
- Algumas permissões do Kubernetes são muito amplas, o que significa que o pod em questão pode não exigir acesso às operações perigosas que suas permissões expõem. Nesse caso, pode ser possível implementar uma política (por exemplo, via OPA Gatekeeper) que impeça o pod de realizar certas operações perigosas ou, melhor ainda, restrinja o pod a um conjunto de operações permitidas e esperadas.
- Use as regras Taints , NodeAffinity ou PodAntiAffinity para isolar pods poderosos de pods não confiáveis ou expostos publicamente, garantindo que eles não sejam executados no mesmo nó.
Como exemplo para a terceira abordagem, a política Rego a seguir pode interromper o ataque de escalação de privilégio apresentado. O ataque abusou dos pods do sistema que podem atualizar as implantações para substituir a conta de serviço de uma implantação existente por uma poderosa. A inspeção do código-fonte desses pods poderosos revelou que eles não precisam da capacidade de alterar a conta de serviço das implantações que atualizam. A política abaixo aproveita isso e proíbe que esses pods atualizem inesperadamente as contas de serviço das implantações. Os usuários do Prisma Cloud no GKE são incentivados a importar essa política como uma regra de admissão definida no Alert.
| 1234567891011121314151617181920212223242526 | match[{“msg”: msg}] { input.request.object.kind == “Deployment” request_by_powerful_dep_update_sa(input.request.userInfo.username) old_spec := input.request.oldObject.spec.template.spec new_spec := input.request.object.spec.template.spec new_service_account := is_updating_the_service_account(old_spec, new_spec) msg := sprintf(“SA ‘%v’ may be compromised, it unexpectedly tried to replace the serviceaccount of ‘deployment/%v:%v’ to ‘%v'”, [input.request.userInfo.username, input.request.object.metadata.namespace, input.request.object.metadata.name, new_service_account])} request_by_powerful_dep_update_sa(username) { # metrics-server pod on GKE username == “system:serviceaccount:kube-system:metrics-server”} { # stackdriver pod on older GKE clusters username == “system:serviceaccount:kube-system:metadata-agent”} is_updating_the_service_account(oldspec, newspec) = new_service_account { oldspec.serviceAccountName != newspec.serviceAccountName new_service_account := newspec.serviceAccountName} { not has_key(oldspec, “serviceAccountName”) new_service_account := newspec.serviceAccountName} has_key(obj, k) { _ = obj[k]} |
Conclusão
À medida que as organizações migram para o Kubernetes, os invasores seguem o exemplo. Amostras recentes de malware, como o Silocap, indicam que os adversários estão evoluindo além de simples técnicas para ataques avançados sob medida do Kubernetes. Contra invasores sofisticados, proteger apenas o perímetro do cluster pode não ser suficiente. Incentivamos os defensores a adotar mecanismos de política e auditoria que possibilitem a detecção e prevenção de atividades subsequentes de invasores de “estágio 2”, e esperamos que esta pesquisa possa destacar como elas podem parecer. Os clientes do Prisma Cloud são incentivados a habilitar nossos recursos de auditoria e controle de admissão do Kubernetes destinados a combater essa ameaça.
Gostaríamos de agradecer ao Google por sua cooperação na resolução desses problemas, a recompensa de recompensas e sua política maravilhosa que duplica as recompensas doadas para instituições de caridade.
A Palo Alto Networks compartilhou essas descobertas, incluindo amostras de arquivos e indicadores de comprometimento, com nossos colegas membros da Cyber Threat Alliance. Os membros do CTA usam essa inteligência para implantar proteções rapidamente para seus clientes e interromper sistematicamente os cibercriminosos mal-intencionados. Saiba mais sobre a Cyber Threat Alliance.






